# Mouse HSC (multiple technologies) {#merged-hsc}
## Introduction
The blood is probably the most well-studied tissue in the single-cell field, mostly because everything is already dissociated "for free".
Of particular interest has been the use of single-cell genomics to study cell fate decisions in haematopoeisis.
Indeed, it was not long ago that dueling interpretations of haematopoeitic stem cell (HSC) datasets were a mainstay of single-cell conferences.
Sadly, these times have mostly passed so we will instead entertain ourselves by combining a small number of these datasets into a single analysis.
## Data loading
```r
library(scuttle)
sce.grun.hsc <- sce.grun.hsc[,sce.grun.hsc$protocol=="sorted hematopoietic stem cells"]
sce.grun.hsc <- logNormCounts(sce.grun.hsc)
set.seed(11001)
library(scran)
dec.grun.hsc <- modelGeneVarByPoisson(sce.grun.hsc)
```
Finally, we will grab the Paul dataset, which we will also subset to only consider the unsorted myeloid population.
This removes the various knockout conditions that just complicates matters.
```r
sce.paul <- sce.paul[,sce.paul$Batch_desc=="Unsorted myeloid"]
sce.paul <- logNormCounts(sce.paul)
set.seed(00010010)
dec.paul <- modelGeneVarByPoisson(sce.paul)
```
## Setting up the merge
```r
common <- Reduce(intersect, list(rownames(sce.nest),
rownames(sce.grun.hsc), rownames(sce.paul)))
length(common)
```
```
## [1] 17147
```
Combining variances to obtain a single set of HVGs.
```r
combined.dec <- combineVar(
dec.nest[common,],
dec.grun.hsc[common,],
dec.paul[common,]
)
hvgs <- getTopHVGs(combined.dec, n=5000)
```
Adjusting for gross differences in sequencing depth.
```r
library(batchelor)
normed.sce <- multiBatchNorm(
Nestorowa=sce.nest[common,],
Grun=sce.grun.hsc[common,],
Paul=sce.paul[common,]
)
```
## Merging the datasets
We turn on `auto.merge=TRUE` to instruct `fastMNN()` to merge the batch that offers the largest number of MNNs.
This aims to perform the "easiest" merges first, i.e., between the most replicate-like batches,
before tackling merges between batches that have greater differences in their population composition.
```r
set.seed(1000010)
merged <- fastMNN(normed.sce, subset.row=hvgs, auto.merge=TRUE)
```
Not too much variance lost inside each batch, hopefully.
We also observe that the algorithm chose to merge the more diverse Nestorowa and Paul datasets before dealing with the HSC-only Grun dataset.
```r
metadata(merged)$merge.info[,c("left", "right", "lost.var")]
```
```
## DataFrame with 2 rows and 3 columns
## left right lost.var
##
## 1 Paul Nestorowa 0.01069374:0.0000000:0.00739465
## 2 Paul,Nestorowa Grun 0.00562344:0.0178334:0.00702615
```
## Combined analyses
The Grun dataset does not contribute to many clusters, consistent with a pure undifferentiated HSC population.
Most of the other clusters contain contributions from the Nestorowa and Paul datasets, though some are unique to the Paul dataset.
This may be due to incomplete correction though we tend to think that this are Paul-specific subpopulations,
given that the Nestorowa dataset does not have similarly sized unique clusters that might represent their uncorrected counterparts.
```r
library(bluster)
colLabels(merged) <- clusterRows(reducedDim(merged),
NNGraphParam(cluster.fun="louvain"))
table(Cluster=colLabels(merged), Batch=merged$batch)
```
```
## Batch
## Cluster Grun Nestorowa Paul
## 1 0 40 206
## 2 0 19 0
## 3 39 353 146
## 4 0 6 29
## 5 0 217 487
## 6 0 162 522
## 7 0 133 191
## 8 22 411 94
## 9 230 315 348
## 10 0 0 385
## 11 0 0 397
```
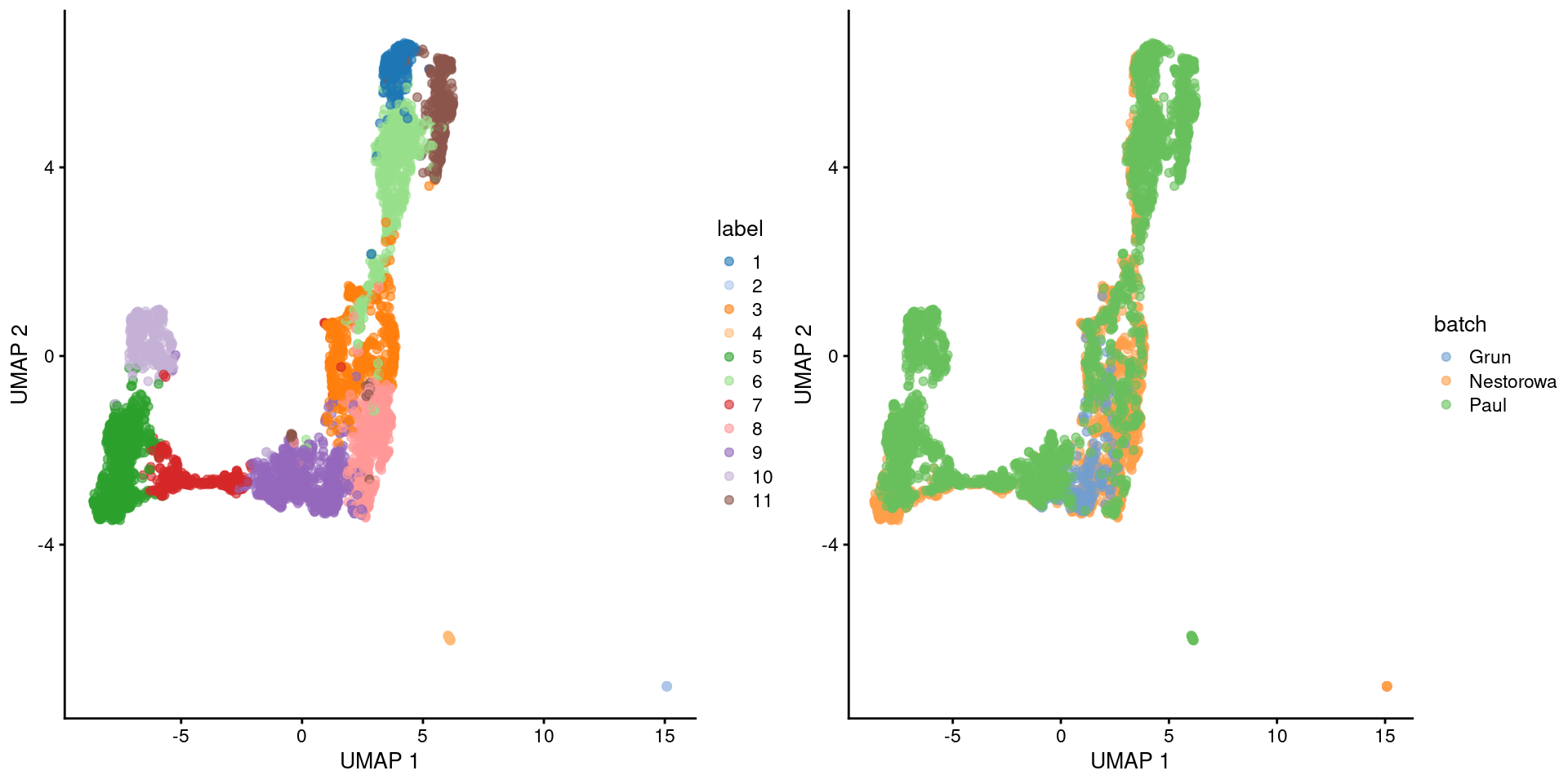
While I prefer $t$-SNE plots,
we'll switch to a UMAP plot to highlight some of the trajectory-like structure across clusters (Figure \@ref(fig:unref-umap-merged-hsc)).
```r
library(scater)
set.seed(101010101)
merged <- runUMAP(merged, dimred="corrected")
gridExtra::grid.arrange(
plotUMAP(merged, colour_by="label"),
plotUMAP(merged, colour_by="batch"),
ncol=2
)
```
(\#fig:unref-umap-merged-hsc)Obligatory UMAP plot of the merged HSC datasets, where each point represents a cell and is colored by the batch of origin (left) or its assigned cluster (right).
In fact, we might as well compute a trajectory right now.
*[TSCAN](https://bioconductor.org/packages/3.13/TSCAN)* constructs a reasonable minimum spanning tree but the path choices are somewhat incongruent with the UMAP coordinates (Figure \@ref(fig:unref-umap-traj-hsc)).
This is most likely due to the fact that *[TSCAN](https://bioconductor.org/packages/3.13/TSCAN)* operates on cluster centroids,
which is simple and efficient but does not consider the variance of cells within each cluster.
It is entirely possible for two well-separated clusters to be closer than two adjacent clusters if the latter span a wider region of the coordinate space.
```r
library(TSCAN)
pseudo.out <- quickPseudotime(merged, use.dimred="corrected", outgroup=TRUE)
```
```r
common.pseudo <- averagePseudotime(pseudo.out$ordering)
plotUMAP(merged, colour_by=I(common.pseudo),
text_by="label", text_colour="red") +
geom_line(data=pseudo.out$connected$UMAP,
mapping=aes(x=dim1, y=dim2, group=edge))
```
(\#fig:unref-umap-traj-hsc)Another UMAP plot of the merged HSC datasets, where each point represents a cell and is colored by its _TSCAN_ pseudotime. The lines correspond to the edges of the MST across cluster centers.
To fix this, we construct the minimum spanning tree using distances based on pairs of mutual nearest neighbors between clusters.
This focuses on the closeness of the boundaries of each pair of clusters rather than their centroids,
ensuring that adjacent clusters are connected even if their centroids are far apart.
Doing so yields a trajectory that is more consistent with the visual connections on the UMAP plot (Figure \@ref(fig:unref-umap-traj-hsc2)).
```r
pseudo.out2 <- quickPseudotime(merged, use.dimred="corrected",
dist.method="mnn", outgroup=TRUE)
common.pseudo2 <- averagePseudotime(pseudo.out2$ordering)
plotUMAP(merged, colour_by=I(common.pseudo2),
text_by="label", text_colour="red") +
geom_line(data=pseudo.out2$connected$UMAP,
mapping=aes(x=dim1, y=dim2, group=edge))
```
(\#fig:unref-umap-traj-hsc2)Yet another UMAP plot of the merged HSC datasets, where each point represents a cell and is colored by its _TSCAN_ pseudotime. The lines correspond to the edges of the MST across cluster centers.