Chapter 14 Multi-sample comparisons
14.1 Motivation
A powerful use of scRNA-seq technology lies in the design of replicated multi-condition experiments to detect changes in composition or expression between conditions. For example, a researcher could use this strategy to detect changes in cell type abundance after drug treatment (Richard et al. 2018) or genetic modifications (Scialdone et al. 2016). This provides more biological insight than conventional scRNA-seq experiments involving only one biological condition, especially if we can relate population changes to specific experimental perturbations.
Differential analyses of multi-condition scRNA-seq experiments can be broadly split into two categories - differential expression (DE) and differential abundance (DA) analyses. The former tests for changes in expression between conditions for cells of the same type that are present in both conditions, while the latter tests for changes in the composition of cell types (or states, etc.) between conditions. In this chapter, we will demonstrate both analyses using data from a study of the early mouse embryo (Pijuan-Sala et al. 2019).
14.2 Setting up the data
Our demonstration scRNA-seq dataset was generated from chimeric mouse embryos at the E8.5 developmental stage. Each chimeric embryo was generated by injecting td-Tomato-positive embryonic stem cells (ESCs) into a wild-type (WT) blastocyst. Unlike in previous experiments (Scialdone et al. 2016), there is no genetic difference between the injected and background cells other than the expression of td-Tomato in the former. Instead, the aim of this “wild-type chimera” study is to determine whether the injection procedure itself introduces differences in lineage commitment compared to the background cells.
The experiment used a paired design with three replicate batches of two samples each. Specifically, each batch contains one sample consisting of td-Tomato positive cells and another consisting of negative cells, obtained by fluorescence-activated cell sorting from a single pool of dissociated cells from 6-7 chimeric embryos. For each sample, scRNA-seq data was generated using the 10X Genomics protocol (Zheng et al. 2017) to obtain 2000-7000 cells.
#--- loading ---#
library(MouseGastrulationData)
sce.chimera <- WTChimeraData(samples=5:10)
sce.chimera
#--- feature-annotation ---#
library(scater)
rownames(sce.chimera) <- uniquifyFeatureNames(
rowData(sce.chimera)$ENSEMBL, rowData(sce.chimera)$SYMBOL)
#--- quality-control ---#
drop <- sce.chimera$celltype.mapped %in% c("stripped", "Doublet")
sce.chimera <- sce.chimera[,!drop]
#--- normalization ---#
sce.chimera <- logNormCounts(sce.chimera)
#--- variance-modelling ---#
library(scran)
dec.chimera <- modelGeneVar(sce.chimera, block=sce.chimera$sample)
chosen.hvgs <- dec.chimera$bio > 0
#--- merging ---#
library(batchelor)
set.seed(01001001)
merged <- correctExperiments(sce.chimera,
batch=sce.chimera$sample,
subset.row=chosen.hvgs,
PARAM=FastMnnParam(
merge.order=list(
list(1,3,5), # WT (3 replicates)
list(2,4,6) # td-Tomato (3 replicates)
)
)
)
#--- clustering ---#
g <- buildSNNGraph(merged, use.dimred="corrected")
clusters <- igraph::cluster_louvain(g)
colLabels(merged) <- factor(clusters$membership)
#--- dimensionality-reduction ---#
merged <- runTSNE(merged, dimred="corrected", external_neighbors=TRUE)
merged <- runUMAP(merged, dimred="corrected", external_neighbors=TRUE)## class: SingleCellExperiment
## dim: 14699 19426
## metadata(2): merge.info pca.info
## assays(3): reconstructed counts logcounts
## rownames(14699): Xkr4 Rp1 ... Vmn2r122 CAAA01147332.1
## rowData names(3): rotation ENSEMBL SYMBOL
## colnames(19426): cell_9769 cell_9770 ... cell_30701 cell_30702
## colData names(13): batch cell ... sizeFactor label
## reducedDimNames(5): corrected pca.corrected.E7.5 pca.corrected.E8.5
## TSNE UMAP
## altExpNames(0):The differential analyses in this chapter will be predicated on many of the pre-processing steps covered previously. For brevity, we will not explicitly repeat them here, only noting that we have already merged cells from all samples into the same coordinate system (Chapter 28.8) and clustered the merged dataset to obtain a common partitioning across all samples (Chapter 10). A brief inspection of the results indicates that clusters contain similar contributions from all batches with only modest differences associated with td-Tomato expression (Figure 14.1).
##
## FALSE TRUE
## 1 546 401
## 2 60 52
## 3 470 398
## 4 469 211
## 5 335 271
## 6 258 249
## 7 1241 967
## 8 203 221
## 9 630 629
## 10 71 181
## 11 47 57
## 12 417 310
## 13 58 0
## 14 209 214
## 15 414 630
## 16 363 509
## 17 234 198
## 18 657 607
## 19 151 303
## 20 579 443
## 21 137 74
## 22 82 78
## 23 155 1
## 24 762 878
## 25 363 497
## 26 1420 716##
## 3 4 5
## 1 224 173 550
## 2 26 30 56
## 3 226 172 470
## 4 78 162 440
## 5 99 227 280
## 6 187 116 204
## 7 300 909 999
## 8 69 134 221
## 9 229 423 607
## 10 114 54 84
## 11 16 31 57
## 12 179 169 379
## 13 2 51 5
## 14 77 97 249
## 15 114 289 641
## 16 183 242 447
## 17 157 81 194
## 18 123 308 833
## 19 106 118 230
## 20 236 238 548
## 21 3 10 198
## 22 27 29 104
## 23 6 84 66
## 24 217 455 968
## 25 132 172 556
## 26 194 870 1072gridExtra::grid.arrange(
plotTSNE(merged, colour_by="tomato", text_by="label"),
plotTSNE(merged, colour_by=data.frame(pool=factor(merged$pool))),
ncol=2
)
Figure 14.1: \(t\)-SNE plot of the WT chimeric dataset, where each point represents a cell and is colored according to td-Tomato expression (left) or batch of origin (right). Cluster numbers are superimposed based on the median coordinate of cells assigned to that cluster.
Ordinarily, we would be obliged to perform marker detection to assign biological meaning to these clusters. For simplicity, we will skip this step by directly using the existing cell type labels provided by Pijuan-Sala et al. (2019). These were obtained by mapping the cells in this dataset to a larger, pre-annotated “atlas” of mouse early embryonic development. While there are obvious similarities, we see that many of our clusters map to multiple labels and vice versa (Figure 14.2), which reflects the difficulties in unambiguously resolving cell types undergoing differentiation.
## [1] 0.5514by.label <- table(colLabels(merged), merged$celltype.mapped)
pheatmap::pheatmap(log2(by.label+1), color=viridis::viridis(101))
Figure 14.2: Heatmap showing the abundance of cells with each combination of cluster (row) and cell type label (column). The color scale represents the log2-count for each combination.
14.3 Differential expression between conditions
14.3.1 Creating pseudo-bulk samples
The most obvious differential analysis is to look for changes in expression between conditions. We perform the DE analysis separately for each label to identify cell type-specific transcriptional effects of injection. The actual DE testing is performed on “pseudo-bulk” expression profiles (Tung et al. 2017), generated by summing counts together for all cells with the same combination of label and sample. This leverages the resolution offered by single-cell technologies to define the labels, and combines it with the statistical rigor of existing methods for DE analyses involving a small number of samples.
# Using 'label' and 'sample' as our two factors; each column of the output
# corresponds to one unique combination of these two factors.
summed <- aggregateAcrossCells(merged,
id=colData(merged)[,c("celltype.mapped", "sample")])
summed## class: SingleCellExperiment
## dim: 14699 186
## metadata(2): merge.info pca.info
## assays(1): counts
## rownames(14699): Xkr4 Rp1 ... Vmn2r122 CAAA01147332.1
## rowData names(3): rotation ENSEMBL SYMBOL
## colnames: NULL
## colData names(16): batch cell ... sample ncells
## reducedDimNames(5): corrected pca.corrected.E7.5 pca.corrected.E8.5
## TSNE UMAP
## altExpNames(0):At this point, it is worth reflecting on the motivations behind the use of pseudo-bulking:
- Larger counts are more amenable to standard DE analysis pipelines designed for bulk RNA-seq data. Normalization is more straightforward and certain statistical approximations are more accurate e.g., the saddlepoint approximation for quasi-likelihood methods or normality for linear models.
- Collapsing cells into samples reflects the fact that our biological replication occurs at the sample level (A. T. L. Lun and Marioni 2017). Each sample is represented no more than once for each condition, avoiding problems from unmodelled correlations between samples. Supplying the per-cell counts directly to a DE analysis pipeline would imply that each cell is an independent biological replicate, which is not true from an experimental perspective. (A mixed effects model can handle this variance structure but involves extra statistical and computational complexity for little benefit, see Crowell et al. (2019).)
- Variance between cells within each sample is masked, provided it does not affect variance across (replicate) samples. This avoids penalizing DEGs that are not uniformly up- or down-regulated for all cells in all samples of one condition. Masking is generally desirable as DEGs - unlike marker genes - do not need to have low within-sample variance to be interesting, e.g., if the treatment effect is consistent across replicate populations but heterogeneous on a per-cell basis. (Of course, high per-cell variability will still result in weaker DE if it affects the variability across populations, while homogeneous per-cell responses will result in stronger DE due to a larger population-level log-fold change. These effects are also largely desirable.)
14.3.2 Performing the DE analysis
14.3.2.1 Introduction
The DE analysis will be performed using quasi-likelihood (QL) methods from the edgeR package (Robinson, McCarthy, and Smyth 2010; Chen, Lun, and Smyth 2016). This uses a negative binomial generalized linear model (NB GLM) to handle overdispersed count data in experiments with limited replication. In our case, we have biological variation with three paired replicates per condition, so edgeR (or its contemporaries) is a natural choice for the analysis.
We do not use all labels for GLM fitting as the strong DE between labels makes it difficult to compute a sensible average abundance to model the mean-dispersion trend. Moreover, label-specific batch effects would not be easily handled with a single additive term in the design matrix for the batch. Instead, we arbitrarily pick one of the labels to use for this demonstration.
label <- "Mesenchyme"
current <- summed[,label==summed$celltype.mapped]
# Creating up a DGEList object for use in edgeR:
library(edgeR)
y <- DGEList(counts(current), samples=colData(current))
y## An object of class "DGEList"
## $counts
## Sample1 Sample2 Sample3 Sample4 Sample5 Sample6
## Xkr4 2 0 0 0 3 0
## Rp1 0 0 1 0 0 0
## Sox17 7 0 3 0 14 9
## Mrpl15 1420 271 1009 379 1578 749
## Rgs20 3 0 1 1 0 0
## 14694 more rows ...
##
## $samples
## group lib.size norm.factors batch cell barcode sample stage tomato pool
## Sample1 1 4607053 1 5 <NA> <NA> 5 E8.5 TRUE 3
## Sample2 1 1064970 1 6 <NA> <NA> 6 E8.5 FALSE 3
## Sample3 1 2494010 1 7 <NA> <NA> 7 E8.5 TRUE 4
## Sample4 1 1028668 1 8 <NA> <NA> 8 E8.5 FALSE 4
## Sample5 1 4290221 1 9 <NA> <NA> 9 E8.5 TRUE 5
## Sample6 1 1950840 1 10 <NA> <NA> 10 E8.5 FALSE 5
## stage.mapped celltype.mapped closest.cell doub.density sizeFactor label
## Sample1 <NA> Mesenchyme <NA> NA NA <NA>
## Sample2 <NA> Mesenchyme <NA> NA NA <NA>
## Sample3 <NA> Mesenchyme <NA> NA NA <NA>
## Sample4 <NA> Mesenchyme <NA> NA NA <NA>
## Sample5 <NA> Mesenchyme <NA> NA NA <NA>
## Sample6 <NA> Mesenchyme <NA> NA NA <NA>
## celltype.mapped.1 sample.1 ncells
## Sample1 Mesenchyme 5 286
## Sample2 Mesenchyme 6 55
## Sample3 Mesenchyme 7 243
## Sample4 Mesenchyme 8 134
## Sample5 Mesenchyme 9 478
## Sample6 Mesenchyme 10 29914.3.2.2 Pre-processing
A typical step in bulk RNA-seq data analyses is to remove samples with very low library sizes due to failed library preparation or sequencing. The very low counts in these samples can be troublesome in downstream steps such as normalization (Chapter 7) or for some statistical approximations used in the DE analysis. In our situation, this is equivalent to removing label-sample combinations that have very few or lowly-sequenced cells. The exact definition of “very low” will vary, but in this case, we remove combinations containing fewer than 10 cells (Crowell et al. 2019). Alternatively, we could apply the outlier-based strategy described in Chapter 6, but this makes the strong assumption that all label-sample combinations have similar numbers of cells that are sequenced to similar depth. We defer to the usual diagnostics for bulk DE analyses to decide whether a particular pseudo-bulk profile should be removed.
## Mode FALSE
## logical 6Another typical step in bulk RNA-seq analyses is to remove genes that are lowly expressed.
This reduces computational work, improves the accuracy of mean-variance trend modelling and decreases the severity of the multiple testing correction.
Here, we use the filterByExpr() function from edgeR to remove genes that are not expressed above a log-CPM threshold in a minimum number of samples (determined from the size of the smallest treatment group in the experimental design).
## Mode FALSE TRUE
## logical 9011 5688Finally, we correct for composition biases by computing normalization factors with the trimmed mean of M-values method (Robinson and Oshlack 2010). We do not need the bespoke single-cell methods described in Chapter 7, as the counts for our pseudo-bulk samples are large enough to apply bulk normalization methods. (Note that edgeR normalization factors are closely related but not the same as the size factors described elsewhere in this book. Size factors are proportional to the product of the normalization factors and the library sizes.)
## group lib.size norm.factors batch cell barcode sample stage tomato pool
## Sample1 1 4607053 1.0683 5 <NA> <NA> 5 E8.5 TRUE 3
## Sample2 1 1064970 1.0487 6 <NA> <NA> 6 E8.5 FALSE 3
## Sample3 1 2494010 0.9582 7 <NA> <NA> 7 E8.5 TRUE 4
## Sample4 1 1028668 0.9774 8 <NA> <NA> 8 E8.5 FALSE 4
## Sample5 1 4290221 0.9707 9 <NA> <NA> 9 E8.5 TRUE 5
## Sample6 1 1950840 0.9817 10 <NA> <NA> 10 E8.5 FALSE 5
## stage.mapped celltype.mapped closest.cell doub.density sizeFactor label
## Sample1 <NA> Mesenchyme <NA> NA NA <NA>
## Sample2 <NA> Mesenchyme <NA> NA NA <NA>
## Sample3 <NA> Mesenchyme <NA> NA NA <NA>
## Sample4 <NA> Mesenchyme <NA> NA NA <NA>
## Sample5 <NA> Mesenchyme <NA> NA NA <NA>
## Sample6 <NA> Mesenchyme <NA> NA NA <NA>
## celltype.mapped.1 sample.1 ncells
## Sample1 Mesenchyme 5 286
## Sample2 Mesenchyme 6 55
## Sample3 Mesenchyme 7 243
## Sample4 Mesenchyme 8 134
## Sample5 Mesenchyme 9 478
## Sample6 Mesenchyme 10 299As part of the usual diagnostics for a bulk RNA-seq DE analysis, we generate a mean-difference (MD) plot for each normalized pseudo-bulk profile (Figure 14.3). This should exhibit a trumpet shape centered at zero indicating that the normalization successfully removed systematic bias between profiles. Lack of zero-centering or dominant discrete patterns at low abundances may be symptomatic of deeper problems with normalization, possibly due to insufficient cells/reads/UMIs composing a particular pseudo-bulk profile.

Figure 14.3: Mean-difference plots of the normalized expression values for each pseudo-bulk sample against the average of all other samples.
We also generate a multi-dimensional scaling (MDS) plot for the pseudo-bulk profiles (Figure 14.4). This is closely related to PCA and allows us to visualize the structure of the data in a manner similar to that described in Chapter 9 (though we rarely have enough pseudo-bulk profiles to make use of techniques like \(t\)-SNE). Here, the aim is to check whether samples separate by our known factors of interest - in this case, injection status. Strong separation foreshadows a large number of DEGs in the subsequent analysis.

Figure 14.4: MDS plot of the pseudo-bulk log-normalized CPMs, where each point represents a sample and is colored by the tomato status.
14.3.2.3 Statistical modelling
We set up the design matrix to block on the batch-to-batch differences across different embryo pools, while retaining an additive term that represents the effect of injection. The latter is represented in our model as the log-fold change in gene expression in td-Tomato-positive cells over their negative counterparts within the same label. Our aim is to test whether this log-fold change is significantly different from zero.
## (Intercept) factor(pool)4 factor(pool)5 factor(tomato)TRUE
## Sample1 1 0 0 1
## Sample2 1 0 0 0
## Sample3 1 1 0 1
## Sample4 1 1 0 0
## Sample5 1 0 1 1
## Sample6 1 0 1 0
## attr(,"assign")
## [1] 0 1 1 2
## attr(,"contrasts")
## attr(,"contrasts")$`factor(pool)`
## [1] "contr.treatment"
##
## attr(,"contrasts")$`factor(tomato)`
## [1] "contr.treatment"We estimate the negative binomial (NB) dispersions with estimateDisp().
The role of the NB dispersion is to model the mean-variance trend (Figure 14.5),
which is not easily accommodated by QL dispersions alone due to the quadratic nature of the NB mean-variance trend.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0103 0.0167 0.0213 0.0202 0.0235 0.0266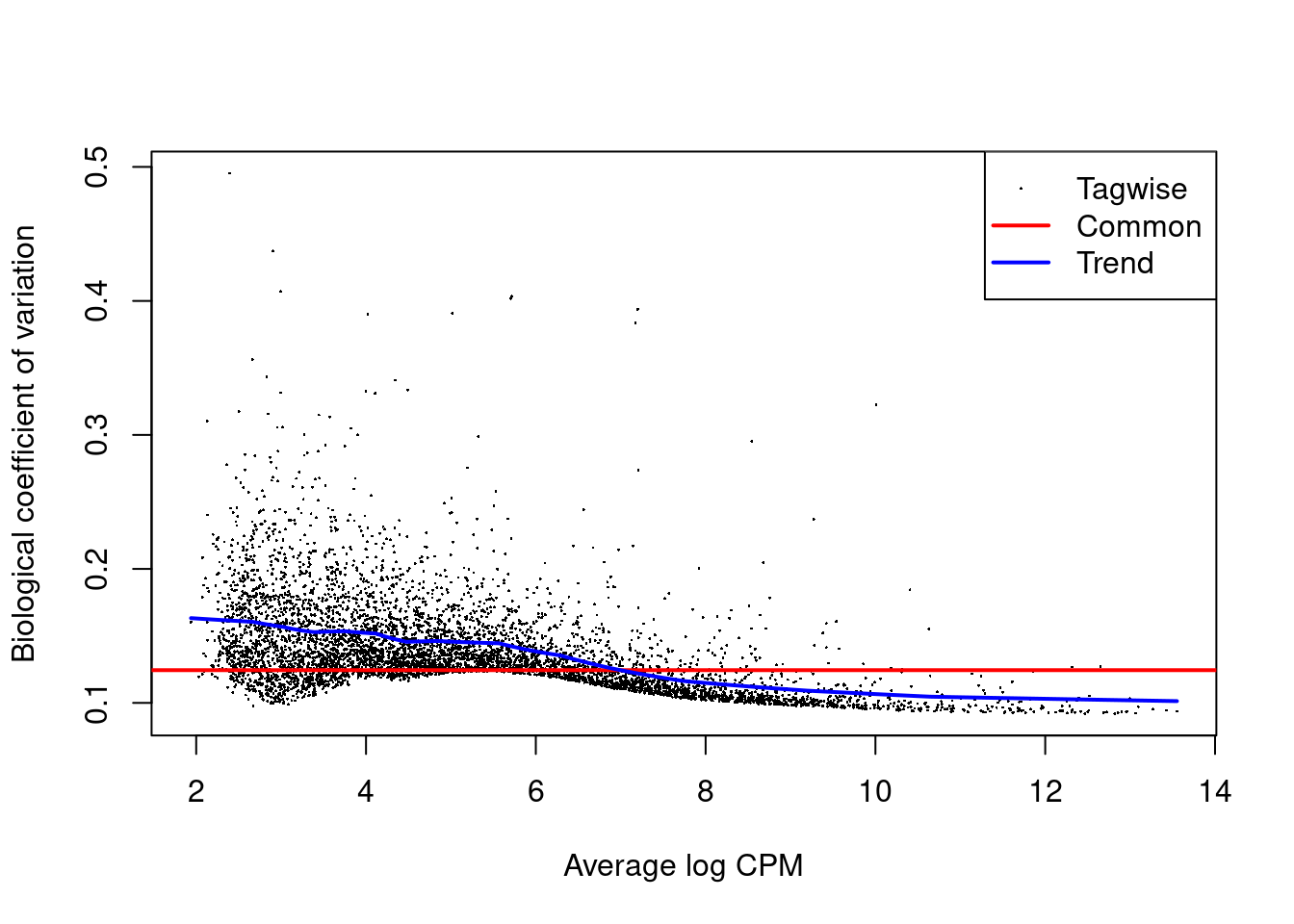
Figure 14.5: Biological coefficient of variation (BCV) for each gene as a function of the average abundance. The BCV is computed as the square root of the NB dispersion after empirical Bayes shrinkage towards the trend. Trended and common BCV estimates are shown in blue and red, respectively.
We also estimate the quasi-likelihood dispersions with glmQLFit() (Chen, Lun, and Smyth 2016).
This fits a GLM to the counts for each gene and estimates the QL dispersion from the GLM deviance.
We set robust=TRUE to avoid distortions from highly variable clusters (Phipson et al. 2016).
The QL dispersion models the uncertainty and variability of the per-gene variance (Figure 14.6) - which is not well handled by the NB dispersions, so the two dispersion types complement each other in the final analysis.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.318 0.714 0.854 0.804 0.913 1.067## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.227 12.675 12.675 12.339 12.675 12.675
Figure 14.6: QL dispersion estimates for each gene as a function of abundance. Raw estimates (black) are shrunk towards the trend (blue) to yield squeezed estimates (red).
We test for differences in expression due to injection using glmQLFTest().
DEGs are defined as those with non-zero log-fold changes at a false discovery rate of 5%.
Very few genes are significantly DE, indicating that injection has little effect on the transcriptome of mesenchyme cells.
(Note that this logic is somewhat circular,
as a large transcriptional effect may have caused cells of this type to be re-assigned to a different label.
We discuss this in more detail in Section 14.6.1 below.)
## factor(tomato)TRUE
## Down 8
## NotSig 5672
## Up 8## Coefficient: factor(tomato)TRUE
## logFC logCPM F PValue FDR
## Phlda2 -4.3874 9.934 1638.59 1.812e-16 1.031e-12
## Erdr1 2.0691 8.833 356.37 1.061e-11 3.017e-08
## Mid1 1.5191 6.931 120.15 1.844e-08 3.497e-05
## H13 -1.0596 7.540 80.80 2.373e-07 2.527e-04
## Kcnq1ot1 1.3763 7.242 83.31 2.392e-07 2.527e-04
## Akr1e1 -1.7206 5.128 79.31 2.665e-07 2.527e-04
## Zdbf2 1.8008 6.797 83.66 6.809e-07 5.533e-04
## Asb4 -0.9235 7.341 53.45 2.918e-06 2.075e-03
## Impact 0.8516 7.353 50.31 4.145e-06 2.620e-03
## Lum -0.6031 9.275 41.67 1.205e-05 6.851e-0314.3.3 Putting it all together
14.3.3.1 Looping across labels
Now that we have laid out the theory underlying the DE analysis,
we repeat this process for each of the labels to identify injection-induced DE in each cell type.
This is conveniently done using the pseudoBulkDGE() function from scran,
which will loop over all labels and apply the exact analysis described above to each label.
(Users can also set method="voom" to perform an equivalent analysis using the voom() pipeline from limma -
see Chapter 33.9 for the full set of function calls.)
# Removing all pseudo-bulk samples with 'insufficient' cells.
summed.filt <- summed[,summed$ncells >= 10]
library(scran)
de.results <- pseudoBulkDGE(summed.filt,
label=summed.filt$celltype.mapped,
design=~factor(pool) + tomato,
coef="tomatoTRUE",
condition=summed.filt$tomato
)The function returns a list of DataFrames containing the DE results for each label.
Each DataFrame also contains the intermediate edgeR objects used in the DE analyses,
which can be used to generate any of previously described diagnostic plots (Figure 14.7).
It is often wise to generate these plots to ensure that any interesting results are not compromised by technical issues.
## DataFrame with 14699 rows and 5 columns
## logFC logCPM F PValue FDR
## <numeric> <numeric> <numeric> <numeric> <numeric>
## Phlda2 -2.489508 12.58150 1207.016 3.33486e-21 1.60507e-17
## Xist -7.978532 8.00166 1092.831 1.27783e-17 3.07510e-14
## Erdr1 1.947170 9.07321 296.937 1.58009e-14 2.53500e-11
## Slc22a18 -4.347153 4.04380 117.389 1.92517e-10 2.31647e-07
## Slc38a4 0.891849 10.24094 113.899 2.52208e-10 2.42776e-07
## ... ... ... ... ... ...
## Ccl27a_ENSMUSG00000095247 NA NA NA NA NA
## CR974586.5 NA NA NA NA NA
## AC132444.6 NA NA NA NA NA
## Vmn2r122 NA NA NA NA NA
## CAAA01147332.1 NA NA NA NA NA
Figure 14.7: Biological coefficient of variation (BCV) for each gene as a function of the average abundance for the allantois pseudo-bulk analysis. Trended and common BCV estimates are shown in blue and red, respectively.
We list the labels that were skipped due to the absence of replicates or contrasts. If it is necessary to extract statistics in the absence of replicates, several strategies can be applied such as reducing the complexity of the model or using a predefined value for the NB dispersion. We refer readers to the edgeR user’s guide for more details.
## [1] "Blood progenitors 1" "Caudal epiblast" "Caudal neurectoderm"
## [4] "ExE ectoderm" "Parietal endoderm" "Stripped"14.3.3.2 Cross-label meta-analyses
We examine the numbers of DEGs at a FDR of 5% for each label using the decideTestsPerLabel() function.
In general, there seems to be very little differential expression that is introduced by injection.
Note that genes listed as NA were either filtered out as low-abundance genes for a given label’s analysis,
or the comparison of interest was not possible for a particular label,
e.g., due to lack of residual degrees of freedom or an absence of samples from both conditions.
## -1 0 1 NA
## Allantois 23 4766 24 9886
## Blood progenitors 2 1 2472 2 12224
## Cardiomyocytes 6 4361 5 10327
## Caudal Mesoderm 2 1742 0 12955
## Def. endoderm 7 1392 2 13298
## Endothelium 3 3222 6 11468
## Erythroid1 12 2777 15 11895
## Erythroid2 5 3389 8 11297
## Erythroid3 13 5048 16 9622
## ExE mesoderm 2 5097 10 9590
## Forebrain/Midbrain/Hindbrain 8 6226 11 8454
## Gut 5 4482 6 10206
## Haematoendothelial progenitors 4 4103 10 10582
## Intermediate mesoderm 4 3072 4 11619
## Mesenchyme 8 5672 8 9011
## NMP 6 4107 10 10576
## Neural crest 6 3311 8 11374
## Paraxial mesoderm 4 4756 5 9934
## Pharyngeal mesoderm 2 5082 9 9606
## Rostral neurectoderm 5 3334 4 11356
## Somitic mesoderm 7 2948 13 11731
## Spinal cord 7 4591 7 10094
## Surface ectoderm 9 5556 8 9126For each gene, we compute the percentage of cell types in which that gene is upregulated or downregulated upon injection. (Here, we consider a gene to be non-DE if it is not retained after filtering.) We see that Xist is consistently downregulated in the injected cells; this is consistent with the fact that the injected cells are male while the background cells are derived from pools of male and female embryos, due to experimental difficulties with resolving sex at this stage. The consistent downregulation of Phlda2 and Cdkn1c in the injected cells is also interesting given that both are imprinted genes. However, some of these commonalities may be driven by shared contamination from ambient RNA - we discuss this further in Section 14.4.
# Upregulated across most cell types.
up.de <- is.de > 0 & !is.na(is.de)
head(sort(rowMeans(up.de), decreasing=TRUE), 10)## Mid1 Erdr1 Impact Mcts2 Kcnq1ot1 Nnat Slc38a4 Zdbf2
## 0.9130 0.7391 0.6087 0.5652 0.5652 0.5217 0.4348 0.3913
## Hopx Peg3
## 0.3913 0.2609# Downregulated across cell types.
down.de <- is.de < 0 & !is.na(is.de)
head(sort(rowMeans(down.de), decreasing=TRUE), 10)## Xist Phlda2 Akr1e1 Cdkn1c H13
## 0.73913 0.73913 0.73913 0.69565 0.52174
## Wfdc2 B930036N10Rik B230312C02Rik Pink1 Mfap2
## 0.21739 0.08696 0.08696 0.08696 0.08696To identify label-specific DE, we use the pseudoBulkSpecific() function to test for significant differences from the average log-fold change over all other labels.
More specifically, the null hypothesis for each label and gene is that the log-fold change lies between zero and the average log-fold change of the other labels.
If a gene rejects this null for our label of interest, we can conclude that it exhibits DE that is more extreme or of the opposite sign compared to that in the majority of other labels (Figure 14.8).
This approach is effectively a poor man’s interaction model that sacrifices the uncertainty of the average for an easier compute.
We note that, while the difference from the average is a good heuristic, there is no guarantee that the top genes are truly label-specific; comparable DE in a subset of the other labels may be offset by weaker effects when computing the average.
de.specific <- pseudoBulkSpecific(summed.filt,
label=summed.filt$celltype.mapped,
design=~factor(pool) + tomato,
coef="tomatoTRUE",
condition=summed.filt$tomato
)
cur.specific <- de.specific[["Allantois"]]
cur.specific <- cur.specific[order(cur.specific$PValue),]
cur.specific## DataFrame with 14699 rows and 6 columns
## logFC logCPM F PValue FDR
## <numeric> <numeric> <numeric> <numeric> <numeric>
## Slc22a18 -4.347153 4.04380 117.3889 1.92517e-10 9.26587e-07
## Acta2 -0.829713 9.12472 55.6350 4.67332e-07 1.12463e-03
## Mxd4 -1.421473 5.64606 50.2112 2.03567e-06 3.26589e-03
## Rbp4 1.874290 4.35449 29.8731 1.53998e-05 1.85298e-02
## Myl9 -0.985541 6.24833 30.6689 5.54072e-05 4.62274e-02
## ... ... ... ... ... ...
## Ccl27a_ENSMUSG00000095247 NA NA NA NA NA
## CR974586.5 NA NA NA NA NA
## AC132444.6 NA NA NA NA NA
## Vmn2r122 NA NA NA NA NA
## CAAA01147332.1 NA NA NA NA NA
## OtherAverage
## <numeric>
## Slc22a18 NA
## Acta2 -0.0267428
## Mxd4 -0.1565876
## Rbp4 -0.1052237
## Myl9 -0.1068453
## ... ...
## Ccl27a_ENSMUSG00000095247 NA
## CR974586.5 NA
## AC132444.6 NA
## Vmn2r122 NA
## CAAA01147332.1 NAsizeFactors(summed.filt) <- NULL
plotExpression(logNormCounts(summed.filt),
features="Rbp4",
x="tomato", colour_by="tomato",
other_fields="celltype.mapped") +
facet_wrap(~celltype.mapped)
Figure 14.8: Distribution of summed log-expression values for Rbp4 in each label of the chimeric embryo dataset. Each facet represents a label with distributions stratified by injection status.
For greater control over the identification of label-specific DE, we can use the output of decideTestsPerLabel() to identify genes that are significant in our label of interest yet not DE in any other label.
As hypothesis tests are not typically geared towards identifying genes that are not DE, we use an ad hoc approach where we consider a gene to be consistent with the null hypothesis for a label if it fails to be detected at a generous FDR threshold of 50%.
We demonstrate this approach below by identifying injection-induced DE genes that are unique to the allantois.
It is straightforward to tune the selection, e.g., to genes that are DE in no more than 90% of other labels by simply relaxing the threshold used to construct not.de.other, or to genes that are DE across multiple labels of interest but not in the rest, and so on.
# Finding all genes that are not remotely DE in all other labels.
remotely.de <- decideTestsPerLabel(de.results, threshold=0.5)
not.de <- remotely.de==0 | is.na(remotely.de)
not.de.other <- rowMeans(not.de[,colnames(not.de)!="Allantois"])==1
# Intersecting with genes that are DE inthe allantois.
unique.degs <- is.de[,"Allantois"]!=0 & not.de.other
unique.degs <- names(which(unique.degs))
# Inspecting the results.
de.allantois <- de.results$Allantois
de.allantois <- de.allantois[unique.degs,]
de.allantois <- de.allantois[order(de.allantois$PValue),]
de.allantois## DataFrame with 5 rows and 5 columns
## logFC logCPM F PValue FDR
## <numeric> <numeric> <numeric> <numeric> <numeric>
## Slc22a18 -4.347153 4.04380 117.3889 1.92517e-10 2.31647e-07
## Rbp4 1.874290 4.35449 29.8731 1.53998e-05 3.36906e-03
## Cfc1 -0.950562 5.74762 23.1430 7.68376e-05 1.23215e-02
## H3f3b 0.321634 12.04012 21.2710 1.25666e-04 1.63468e-02
## Cryab -0.995629 5.28422 19.5921 1.99204e-04 2.45838e-02The main caveat is that differences in power between labels require some caution when interpreting label specificity. For example, Figure 14.9 shows that the top-ranked allantois-specific gene exhibits some evidence of DE in other labels but was not detected for various reasons like low abundance or insufficient replicates. A more correct but complex approach would be to fit a interaction model to the pseudo-bulk profiles for each pair of labels, where the interaction is between the coefficient of interest and the label identity; this is left as an exercise for the reader.
plotExpression(logNormCounts(summed.filt),
features="Slc22a18",
x="tomato", colour_by="tomato",
other_fields="celltype.mapped") +
facet_wrap(~celltype.mapped)
Figure 14.9: Distribution of summed log-expression values for each label in the chimeric embryo dataset. Each facet represents a label with distributions stratified by injection status.
14.4 Avoiding problems with ambient RNA
14.4.1 Motivation
Ambient contamination is a phenomenon that is generally most pronounced in massively multiplexed scRNA-seq protocols. Briefly, extracellular RNA (most commonly released upon cell lysis) is captured along with each cell in its reaction chamber, contributing counts to genes that are not otherwise expressed in that cell (see Section 15.2). Differences in the ambient profile across samples are not uncommon when dealing with strong experimental perturbations where strong expression of a gene in a condition-specific cell type can “bleed over” into all other cell types in the same sample. This is problematic for DE analyses between conditions, as DEGs detected for a particular cell type may be driven by differences in the ambient profiles rather than any intrinsic change in gene regulation.
To illustrate, we consider the Tal1-knockout (KO) chimera data from Pijuan-Sala et al. (2019). This is very similar to the WT chimera dataset we previously examined, only differing in that the Tal1 gene was knocked out in the injected cells. Tal1 is a transcription factor that has known roles in erythroid differentiation; the aim of the experiment was to determine if blocking of the erythroid lineage diverted cells to other developmental fates. (To cut a long story short: yes, it did.)
library(MouseGastrulationData)
sce.tal1 <- Tal1ChimeraData()
library(scuttle)
rownames(sce.tal1) <- uniquifyFeatureNames(
rowData(sce.tal1)$ENSEMBL,
rowData(sce.tal1)$SYMBOL
)
sce.tal1## class: SingleCellExperiment
## dim: 29453 56122
## metadata(0):
## assays(1): counts
## rownames(29453): Xkr4 Gm1992 ... CAAA01147332.1 tomato-td
## rowData names(2): ENSEMBL SYMBOL
## colnames(56122): cell_1 cell_2 ... cell_56121 cell_56122
## colData names(9): cell barcode ... pool sizeFactor
## reducedDimNames(1): pca.corrected
## altExpNames(0):We will perform a DE analysis between WT and KO cells labelled as “neural crest”. We observe that the strongest DEGs are the hemoglobins, which are downregulated in the injected cells. This is rather surprising as these cells are distinct from the erythroid lineage and should not express hemoglobins at all. The most sober explanation is that the background samples contain more hemoglobin transcripts in the ambient solution due to leakage from erythrocytes (or their precursors) during sorting and dissociation.
summed.tal1 <- aggregateAcrossCells(sce.tal1,
ids=DataFrame(sample=sce.tal1$sample,
label=sce.tal1$celltype.mapped)
)
summed.tal1$block <- summed.tal1$sample %% 2 == 0 # Add blocking factor.
# Subset to our neural crest cells.
summed.neural <- summed.tal1[,summed.tal1$label=="Neural crest"]
summed.neural## class: SingleCellExperiment
## dim: 29453 4
## metadata(0):
## assays(1): counts
## rownames(29453): Xkr4 Gm1992 ... CAAA01147332.1 tomato-td
## rowData names(2): ENSEMBL SYMBOL
## colnames: NULL
## colData names(13): cell barcode ... ncells block
## reducedDimNames(1): pca.corrected
## altExpNames(0):# Standard edgeR analysis, as described above.
res.neural <- pseudoBulkDGE(summed.neural,
label=summed.neural$label,
design=~factor(block) + tomato,
coef="tomatoTRUE",
condition=summed.neural$tomato)
summarizeTestsPerLabel(decideTestsPerLabel(res.neural))## -1 0 1 NA
## Neural crest 351 9818 481 18803# Summary of the direction of log-fold changes.
tab.neural <- res.neural[[1]]
tab.neural <- tab.neural[order(tab.neural$PValue),]
head(tab.neural, 10)## DataFrame with 10 rows and 5 columns
## logFC logCPM F PValue FDR
## <numeric> <numeric> <numeric> <numeric> <numeric>
## Xist -7.555686 8.21232 6657.298 0.00000e+00 0.00000e+00
## Hbb-bh1 -8.091042 9.15972 10758.256 0.00000e+00 0.00000e+00
## Hbb-y -8.415622 8.35705 7364.290 0.00000e+00 0.00000e+00
## Hba-x -7.724803 8.53284 7896.457 0.00000e+00 0.00000e+00
## Hba-a1 -8.596706 6.74429 2756.573 0.00000e+00 0.00000e+00
## Hba-a2 -8.866232 5.81300 1517.726 1.72378e-310 3.05972e-307
## Erdr1 1.889536 7.61593 1407.112 2.34678e-289 3.57046e-286
## Cdkn1c -8.864528 4.96097 814.936 8.79979e-173 1.17147e-169
## Uba52 -0.879668 8.38618 424.191 1.86585e-92 2.20792e-89
## Grb10 -1.403427 6.58314 401.353 1.13898e-87 1.21302e-84As an aside, it is worth mentioning that the “replicates” in this study are more technical than biological, so some exaggeration of the significance of the effects is to be expected. Nonetheless, it is a useful dataset to demonstrate some strategies for mitigating issues caused by ambient contamination.
14.4.2 Finding affected DEGs
14.4.2.1 By estimating ambient contamination
As shown above, the presence of ambient contamination makes it difficult to interpret multi-condition DE analyses.
To mitigate its effects, we need to obtain an estimate of the ambient “expression” profile from the raw count matrix for each sample.
We follow the approach used in emptyDrops() (Lun et al. 2019) and consider all barcodes with total counts below 100 to represent empty droplets.
We then sum the counts for each gene across these barcodes to obtain an expression vector representing the ambient profile for each sample.
library(DropletUtils)
ambient <- vector("list", ncol(summed.neural))
# Looping over all raw (unfiltered) count matrices and
# computing the ambient profile based on its low-count barcodes.
# Turning off rounding, as we know this is count data.
for (s in seq_along(ambient)) {
raw.tal1 <- Tal1ChimeraData(type="raw", samples=s)[[1]]
ambient[[s]] <- estimateAmbience(counts(raw.tal1),
good.turing=FALSE, round=FALSE)
}
# Cleaning up the output for pretty printing.
ambient <- do.call(cbind, ambient)
colnames(ambient) <- seq_len(ncol(ambient))
rownames(ambient) <- uniquifyFeatureNames(
rowData(raw.tal1)$ENSEMBL,
rowData(raw.tal1)$SYMBOL
)
head(ambient)## 1 2 3 4
## Xkr4 1 0 0 0
## Gm1992 0 0 0 0
## Gm37381 1 0 1 0
## Rp1 0 1 0 1
## Sox17 76 76 31 53
## Gm37323 0 0 0 0For each sample, we determine the maximum proportion of the count for each gene that could be attributed to ambient contamination.
This is done by scaling the ambient profile in ambient to obtain a per-gene expected count from ambient contamination, with which we compute the \(p\)-value for observing a count equal to or lower than that in summed.neural.
We perform this for a range of scaling factors and identify the largest factor that yields a \(p\)-value above a given threshold.
The scaled ambient profile represents the upper bound of the contribution to each sample from ambient contamination.
We deliberately use an upper bound so that our next step will aggressively remove any gene that is potentially problematic.
## [,1] [,2] [,3] [,4]
## Xkr4 NaN NaN NaN NaN
## Gm1992 NaN NaN NaN NaN
## Gm37381 NaN NaN NaN NaN
## Rp1 NaN NaN NaN NaN
## Sox17 0.1775 0.1833 0.468 1
## Gm37323 NaN NaN NaN NaNGenes in which over 10% of the counts are ambient-derived (averaged across samples) are subsequently discarded from our analysis. For balanced designs, this threshold prevents ambient contribution from biasing the true fold-change by more than 10%, which is a tolerable margin of error for most applications. (Unbalanced designs may warrant the use of a weighted average to account for sample size differences between groups.) This approach yields a slightly smaller list of DEGs without the hemoglobins, which is encouraging as it suggests that any other (less obvious) effects of ambient contamination have also been removed.
contamination <- rowMeans(max.ambient, na.rm=TRUE)
non.ambient <- contamination <= 0.1
summary(non.ambient)## Mode FALSE TRUE NA's
## logical 1475 15306 12672okay.genes <- names(non.ambient)[which(non.ambient)]
tab.neural2 <- tab.neural[rownames(tab.neural) %in% okay.genes,]
table(Direction=tab.neural2$logFC > 0, Significant=tab.neural2$FDR <= 0.05)## Significant
## Direction FALSE TRUE
## FALSE 4820 317
## TRUE 4781 452## DataFrame with 10 rows and 5 columns
## logFC logCPM F PValue FDR
## <numeric> <numeric> <numeric> <numeric> <numeric>
## Xist -7.555686 8.21232 6657.298 0.00000e+00 0.00000e+00
## Erdr1 1.889536 7.61593 1407.112 2.34678e-289 3.57046e-286
## Uba52 -0.879668 8.38618 424.191 1.86585e-92 2.20792e-89
## Grb10 -1.403427 6.58314 401.353 1.13898e-87 1.21302e-84
## Gt(ROSA)26Sor 1.481294 5.71617 351.940 2.80072e-77 2.71160e-74
## Fdps 0.981388 7.21805 337.159 3.67655e-74 3.26294e-71
## Mest 0.549349 10.98269 319.697 1.79833e-70 1.47324e-67
## Impact 1.396666 5.71801 314.700 2.05057e-69 1.55990e-66
## H13 -1.481658 5.90902 301.675 1.17372e-66 8.33343e-64
## Msmo1 1.493771 5.43923 301.066 1.57983e-66 1.05158e-63A softer approach is to simply report the average contaminating percentage for each gene in the table of DE statistics.
This allows readers to make up their own minds as to whether a particular DEG’s effect is driven by ambient contamination, in much the same way as described for low-quality cells in Section 6.6.
Indeed, it is worth remembering that maximumAmbience() will report the maximum possible contamination rather than attempting to estimate the actual level of contamination, and filtering on the former may be overly conservative.
This is especially true for cell populations that are contributing to the differences in the ambient pool; in the most extreme case, the reported maximum contamination would be 100% for cell types with an expression profile that is identical to the ambient pool.
tab.neural3 <- tab.neural
tab.neural3$contamination <- contamination[rownames(tab.neural3)]
head(tab.neural3)## DataFrame with 6 rows and 6 columns
## logFC logCPM F PValue FDR contamination
## <numeric> <numeric> <numeric> <numeric> <numeric> <numeric>
## Xist -7.55569 8.21232 6657.30 0.00000e+00 0.00000e+00 0.0605735
## Hbb-bh1 -8.09104 9.15972 10758.26 0.00000e+00 0.00000e+00 0.9900717
## Hbb-y -8.41562 8.35705 7364.29 0.00000e+00 0.00000e+00 0.9674483
## Hba-x -7.72480 8.53284 7896.46 0.00000e+00 0.00000e+00 0.9945348
## Hba-a1 -8.59671 6.74429 2756.57 0.00000e+00 0.00000e+00 0.8626846
## Hba-a2 -8.86623 5.81300 1517.73 1.72378e-310 3.05972e-307 0.735140314.4.2.2 With prior knowledge
Another strategy to estimating the ambient proportions involves the use of prior knowledge of mutually exclusive gene expression profiles (Young and Behjati 2018).
In this case, we assume (reasonably) that hemoglobins should not be expressed in neural crest cells and use this to estimate the contamination in each sample.
This is achieved with the controlAmbience() function, which scales the ambient profile so that the hemoglobin coverage is the same as the corresponding sample of summed.neural.
From these profiles, we compute proportions of ambient contamination that are used to mark or filter out affected genes in the same manner as described above.
is.hbb <- grep("^Hb[ab]-", rownames(summed.neural))
alt.prop <- controlAmbience(counts(summed.neural), ambient,
features=is.hbb, mode="proportion")
head(alt.prop)## 1 2 3 4
## Xkr4 NaN NaN NaN NaN
## Gm1992 NaN NaN NaN NaN
## Gm37381 NaN NaN NaN NaN
## Rp1 NaN NaN NaN NaN
## Sox17 0.06774 0.08798 0.4796 1
## Gm37323 NaN NaN NaN NaN## Mode FALSE TRUE NA's
## logical 1388 15393 12672okay.genes <- names(alt.non.ambient)[which(alt.non.ambient)]
tab.neural4 <- tab.neural[rownames(tab.neural) %in% okay.genes,]
head(tab.neural4)## DataFrame with 6 rows and 5 columns
## logFC logCPM F PValue FDR
## <numeric> <numeric> <numeric> <numeric> <numeric>
## Xist -7.555686 8.21232 6657.298 0.00000e+00 0.00000e+00
## Erdr1 1.889536 7.61593 1407.112 2.34678e-289 3.57046e-286
## Uba52 -0.879668 8.38618 424.191 1.86585e-92 2.20792e-89
## Grb10 -1.403427 6.58314 401.353 1.13898e-87 1.21302e-84
## Gt(ROSA)26Sor 1.481294 5.71617 351.940 2.80072e-77 2.71160e-74
## Fdps 0.981388 7.21805 337.159 3.67655e-74 3.26294e-71Any highly expressed cell type-specific gene is a candidate for this procedure, most typically in cell types that are highly specialized towards manufacturing a protein product. Aside from hemoglobin, we could use immunoglobulins in populations containing B cells, or insulin and glucagon in pancreas datasets (Figure 11.6). The experimental setting may also provide some genes that must only be present in the ambient solution; for example, the mitochondrial transcripts can be used to estimate ambient contamination in single-nucleus RNA-seq, while Xist can be used for datasets involving mixtures of male and female cells (where the contaminating percentages are estimated from the profiles of male cells only).
If appropriate control features are available, this approach allows us to obtain a more accurate estimate of the contamination in each pseudo-bulk sample compared to the upper bound provided by maximumAmbience().
This avoids the removal of genuine DEGs due to overestimation fo the ambient contamination from the latter.
However, the performance of this approach is fully dependent on the suitability of the control features - if a “control” feature is actually genuinely expressed in a cell type, the ambient contribution will be overestimated.
A simple mitigating strategy is to simply take the lower of the proportions from controlAmbience() and maximumAmbience(), with the idea being that the latter will avoid egregious overestimation when the control set is misspecified.
14.4.2.3 Without an ambient profile
An estimate of the ambient profile is rarely available for public datasets where only the per-cell count matrices are provided. In such cases, we must instead use the rest of the dataset to infer something about the effects of ambient contamination. The most obvious approach is construct a proxy ambient profile by summing the counts for all cells from each sample, which can be used in place of the actual profile in the previous calculations. This assumes equal contributions from all labels to the ambient pool, which is not entirely unrealistic (Figure 14.10) though some discrepancies can be expected due to the presence of particularly fragile cell types or extracellular RNA.
proxy.ambient <- aggregateAcrossCells(summed.tal1,
ids=summed.tal1$sample)
par(mfrow=c(2,2))
for (i in seq_len(ncol(proxy.ambient))) {
true <- ambient[,i]
proxy <- assay(proxy.ambient)[,i]
logged <- edgeR::cpm(cbind(proxy, true), log=TRUE, prior.count=2)
logFC <- logged[,1] - logged[,2]
abundance <- rowMeans(logged)
plot(abundance, logFC, main=paste("Sample", i))
}
Figure 14.10: MA plots of the log-fold change of the proxy ambient profile over the real profile for each sample in the Tal1 chimera dataset.
We can also mitigate the effect of ambient contamination by focusing on label-specific DEGs. Contamination-driven DEGs should be systematically present in comparisons for all labels, and thus can be eliminated by simply ignoring all genes that are significant in a majority of these comparisons (Section 14.3.3.2). The obvious drawback of this approach is that it discounts genuine DEGs that have a consistent effect in most/all labels, though one could perhaps argue that such “global” DEGs are not the main features of interest in label-specific analyses. It is also complicated by fluctuations in detection power across comparisons involving different numbers of cells - or replicates, after filtering pseudo-bulk profiles by the number of cells.
res.tal1 <- pseudoBulkDGE(summed.tal1,
label=summed.tal1$label,
design=~factor(block) + tomato,
coef="tomatoTRUE",
condition=summed.tal1$tomato)
# DE in the same direction across most labels.
tal1.de <- decideTestsPerLabel(res.tal1)
up.de <- rowMeans(tal1.de > 0 & !is.na(tal1.de))
down.de <- rowMeans(tal1.de < 0 & !is.na(tal1.de))
# Inspecting our neural crest results again.
tab.neural.again <- res.tal1[["Neural crest"]]
tab.neural.again$OtherUp <- up.de
tab.neural.again$OtherDown <- down.de
head(tab.neural.again[order(tab.neural.again$PValue),], 10)## DataFrame with 10 rows and 7 columns
## logFC logCPM F PValue FDR OtherUp
## <numeric> <numeric> <numeric> <numeric> <numeric> <numeric>
## Xist -7.555686 8.21232 6657.298 0.00000e+00 0.00000e+00 0.000000
## Hbb-bh1 -8.091042 9.15972 10758.256 0.00000e+00 0.00000e+00 0.000000
## Hbb-y -8.415622 8.35705 7364.290 0.00000e+00 0.00000e+00 0.000000
## Hba-x -7.724803 8.53284 7896.457 0.00000e+00 0.00000e+00 0.000000
## Hba-a1 -8.596706 6.74429 2756.573 0.00000e+00 0.00000e+00 0.000000
## Hba-a2 -8.866232 5.81300 1517.726 1.72378e-310 3.05972e-307 0.000000
## Erdr1 1.889536 7.61593 1407.112 2.34678e-289 3.57046e-286 0.444444
## Cdkn1c -8.864528 4.96097 814.936 8.79979e-173 1.17147e-169 0.000000
## Uba52 -0.879668 8.38618 424.191 1.86585e-92 2.20792e-89 0.000000
## Grb10 -1.403427 6.58314 401.353 1.13898e-87 1.21302e-84 0.000000
## OtherDown
## <numeric>
## Xist 0.851852
## Hbb-bh1 0.925926
## Hbb-y 0.851852
## Hba-x 0.814815
## Hba-a1 0.777778
## Hba-a2 0.777778
## Erdr1 0.000000
## Cdkn1c 0.814815
## Uba52 0.814815
## Grb10 0.777778# Actually removing those with a DE majority across labels.
ignore <- up.de > 0.5 | down.de > 0.5
tab.neural.again <- tab.neural.again[!ignore,]
head(tab.neural.again[order(tab.neural.again$PValue),], 10)## DataFrame with 10 rows and 7 columns
## logFC logCPM F PValue FDR OtherUp
## <numeric> <numeric> <numeric> <numeric> <numeric> <numeric>
## Erdr1 1.889536 7.61593 1407.1122 2.34678e-289 3.57046e-286 0.444444
## Fdps 0.981388 7.21805 337.1586 3.67655e-74 3.26294e-71 0.222222
## Msmo1 1.493771 5.43923 301.0658 1.57983e-66 1.05158e-63 0.222222
## Hmgcs1 1.250024 5.70837 252.1105 3.95670e-56 2.21783e-53 0.222222
## Idi1 1.173709 5.37688 180.8890 6.68049e-41 2.73643e-38 0.148148
## Ddit4 0.844702 5.59699 109.5505 1.63456e-25 3.95637e-23 0.444444
## Scd2 0.798049 5.70852 103.7377 2.98274e-24 7.05915e-22 0.259259
## Sox9 0.537460 7.17373 99.3336 2.69822e-23 5.74720e-21 0.148148
## Nkd1 0.719043 5.92690 93.9636 3.96635e-22 8.28267e-20 0.185185
## Fdft1 0.841061 5.32293 89.8826 3.06448e-21 5.93394e-19 0.185185
## OtherDown
## <numeric>
## Erdr1 0.0000000
## Fdps 0.1851852
## Msmo1 0.1851852
## Hmgcs1 0.1111111
## Idi1 0.1111111
## Ddit4 0.0000000
## Scd2 0.0740741
## Sox9 0.0740741
## Nkd1 0.0740741
## Fdft1 0.1111111The common theme here is that, in the absence of an ambient profile, we are using all labels as a proxy for the ambient effect.
This can have unpredictable consequences as the results for each label are now dependent on the behavior of the entire dataset.
For example, the metrics are susceptible to the idiosyncrasies of clustering where one cell type may be represented in multple related clusters that distort the percentages in up.de and down.de or the average log-fold change.
The metrics may also be invalidated in analyses of a subset of the data - for example, a subclustering analysis focusing on a particular cell type may mark all relevant DEGs as problematic because they are consistently DE in all subtypes.
14.4.3 Subtracting ambient counts
It is worth commenting on the seductive idea of subtracting the ambient counts from the pseudo-bulk samples. This may seem like the most obvious approach for removing ambient contamination, but unfortunately, subtracted counts have unpredictable statistical properties due the distortion of the mean-variance relationship. Minor relative fluctuations at very large counts become large fold-changes after subtraction, manifesting as spurious DE in genes where a substantial proportion of counts is derived from the ambient solution. For example, several hemoglobin genes retain strong DE even after subtraction of the scaled ambient profile.
scaled.ambient <- controlAmbience(counts(summed.neural), ambient,
features=is.hbb, mode="profile")
subtracted <- counts(summed.neural) - scaled.ambient
subtracted <- round(subtracted)
subtracted[subtracted < 0] <- 0
subtracted[is.hbb,]## [,1] [,2] [,3] [,4]
## Hbb-bt 0 0 7 18
## Hbb-bs 1 2 31 42
## Hbb-bh2 0 0 0 0
## Hbb-bh1 2 0 0 0
## Hbb-y 0 0 39 107
## Hba-x 1 1 0 0
## Hba-a1 0 0 365 452
## Hba-a2 0 0 314 329Another tempting approach is to use interaction models to implicitly subtract the ambient effect during GLM fitting. The assumption is that, for a genuine DEG, the log-fold change within cells is larger in magnitude than that in the ambient solution. This is based on the expectation that any DE in the latter is “diluted” by contributions from cell types where that gene is not DE. Unfortunately, this is not always the case; a DE analysis of the ambient counts indicates that the hemoglobin log-fold change is actually stronger in the neural crest cells compared to the ambient solution, which leads to the rather awkward conclusion that the WT neural crest cells are expressing hemoglobin beyond that explained by ambient contamination.
y.ambient <- DGEList(ambient, samples=colData(summed.neural))
y.ambient <- y.ambient[filterByExpr(y.ambient, group=y.ambient$samples$tomato),]
y.ambient <- calcNormFactors(y.ambient)
design <- model.matrix(~factor(block) + tomato, y.ambient$samples)
y.ambient <- estimateDisp(y.ambient, design)
fit.ambient <- glmQLFit(y.ambient, design, robust=TRUE)
res.ambient <- glmQLFTest(fit.ambient, coef=ncol(design))
summary(decideTests(res.ambient))## tomatoTRUE
## Down 1910
## NotSig 7683
## Up 1645## Coefficient: tomatoTRUE
## logFC logCPM F PValue FDR
## Hbb-y -5.267 12.803 15115 3.523e-81 3.959e-77
## Hbb-bh1 -5.075 13.725 14002 8.892e-80 4.996e-76
## Hba-x -4.827 13.122 13317 3.135e-79 1.175e-75
## Hba-a1 -4.662 10.734 11095 1.146e-76 3.220e-73
## Hba-a2 -4.521 9.480 8411 1.246e-72 2.800e-69
## Blvrb -4.319 7.649 4129 3.066e-62 5.742e-59
## Xist -4.376 7.484 3891 1.864e-61 2.993e-58
## Gypa -5.138 7.213 3808 3.833e-61 5.384e-58
## Hbb-bs -4.941 7.209 3604 3.728e-60 4.655e-57
## Car2 -3.499 8.534 4448 5.589e-60 6.281e-57(One possible explanation is that erythrocyte fragments are present in the cell-containing libraries but are not used to estimate the ambient profile, presumably because the UMI counts are too high for fragment-containing libraries to be treated as empty. Technically speaking, this is not incorrect as, after all, those libraries are not actually empty (Section 15.2). In effect, every cell in the WT sample is a fractional multiplet with partial erythrocyte identity from the included fragments, which results in stronger log-fold changes between genotypes for hemoglobin compared to those for the ambient solution.)
That aside, there are other issues with implicit subtraction in the fitted GLM that warrant caution with its use. This strategy precludes detection of DEGs that are common to all cell types as there is no longer a dilution effect being applied to the log-fold change in the ambient solution. It requires inclusion of the ambient profiles in the model, which is cause for at least some concern as they are unlikely to have the same degree of variability as the cell-derived pseudo-bulk profiles. Interpretation is also complicated by the fact that we are only interested in log-fold changes that are more extreme in the cells compared to the ambient solution; a non-zero interaction term is not sufficient for removing spurious DE.
14.5 Differential abundance between conditions
14.5.1 Overview
In a DA analysis, we test for significant changes in per-label cell abundance across conditions. This will reveal which cell types are depleted or enriched upon treatment, which is arguably just as interesting as changes in expression within each cell type. The DA analysis has a long history in flow cytometry (Finak et al. 2014; A. T. L. Lun, Richard, and Marioni 2017) where it is routinely used to examine the effects of different conditions on the composition of complex cell populations. By performing it here, we effectively treat scRNA-seq as a “super-FACS” technology for defining relevant subpopulations using the entire transcriptome.
We prepare for the DA analysis by quantifying the number of cells assigned to each label (or cluster) in our WT chimeric experiment. In this case, we are aiming to identify labels that change in abundance among the compartment of injected cells compared to the background.
abundances <- table(merged$celltype.mapped, merged$sample)
abundances <- unclass(abundances)
head(abundances)##
## 5 6 7 8 9 10
## Allantois 97 15 139 127 318 259
## Blood progenitors 1 6 3 16 6 8 17
## Blood progenitors 2 31 8 28 21 43 114
## Cardiomyocytes 85 21 79 31 174 211
## Caudal Mesoderm 10 10 9 3 10 29
## Caudal epiblast 2 2 0 0 22 4514.5.2 Performing the DA analysis
Our DA analysis will again be performed with the edgeR package. This allows us to take advantage of the NB GLM methods to model overdispersed count data in the presence of limited replication - except that the counts are not of reads per gene, but of cells per label (A. T. L. Lun, Richard, and Marioni 2017). The aim is to share information across labels to improve our estimates of the biological variability in cell abundance between replicates.
# Attaching some column metadata.
extra.info <- colData(merged)[match(colnames(abundances), merged$sample),]
y.ab <- DGEList(abundances, samples=extra.info)
y.ab## An object of class "DGEList"
## $counts
##
## 5 6 7 8 9 10
## Allantois 97 15 139 127 318 259
## Blood progenitors 1 6 3 16 6 8 17
## Blood progenitors 2 31 8 28 21 43 114
## Cardiomyocytes 85 21 79 31 174 211
## Caudal Mesoderm 10 10 9 3 10 29
## 29 more rows ...
##
## $samples
## group lib.size norm.factors batch cell barcode sample stage
## 5 1 2298 1 5 cell_9769 AAACCTGAGACTGTAA 5 E8.5
## 6 1 1026 1 6 cell_12180 AAACCTGCAGATGGCA 6 E8.5
## 7 1 2740 1 7 cell_13227 AAACCTGAGACAAGCC 7 E8.5
## 8 1 2904 1 8 cell_16234 AAACCTGCAAACCCAT 8 E8.5
## 9 1 4057 1 9 cell_19332 AAACCTGCAACGATCT 9 E8.5
## 10 1 6401 1 10 cell_23875 AAACCTGAGGCATGTG 10 E8.5
## tomato pool stage.mapped celltype.mapped closest.cell
## 5 TRUE 3 E8.25 Mesenchyme cell_24159
## 6 FALSE 3 E8.25 Somitic mesoderm cell_63247
## 7 TRUE 4 E8.5 Somitic mesoderm cell_25454
## 8 FALSE 4 E8.25 ExE mesoderm cell_139075
## 9 TRUE 5 E8.0 ExE mesoderm cell_116116
## 10 FALSE 5 E8.5 Forebrain/Midbrain/Hindbrain cell_39343
## doub.density sizeFactor label
## 5 0.029850 1.6349 19
## 6 0.291916 2.5981 6
## 7 0.601740 1.5939 17
## 8 0.004733 0.8707 9
## 9 0.079415 0.8933 15
## 10 0.040747 0.3947 1We filter out low-abundance labels as previously described. This avoids cluttering the result table with very rare subpopulations that contain only a handful of cells. For a DA analysis of cluster abundances, filtering is generally not required as most clusters will not be of low-abundance (otherwise there would not have been enough evidence to define the cluster in the first place).
## Mode FALSE TRUE
## logical 10 24Unlike DE analyses, we do not perform an additional normalization step with calcNormFactors().
This means that we are only normalizing based on the “library size”, i.e., the total number of cells in each sample.
Any changes we detect between conditions will subsequently represent differences in the proportion of cells in each cluster.
The motivation behind this decision is discussed in more detail in Section 14.5.3.
We formulate the design matrix with a blocking factor for the batch of origin for each sample and an additive term for the td-Tomato status (i.e., injection effect). Here, the log-fold change in our model refers to the change in cell abundance after injection, rather than the change in gene expression.
We use the estimateDisp() function to estimate the NB dispersion for each cluster (Figure 14.11).
We turn off the trend as we do not have enough points for its stable estimation.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0614 0.0614 0.0614 0.0614 0.0614 0.0614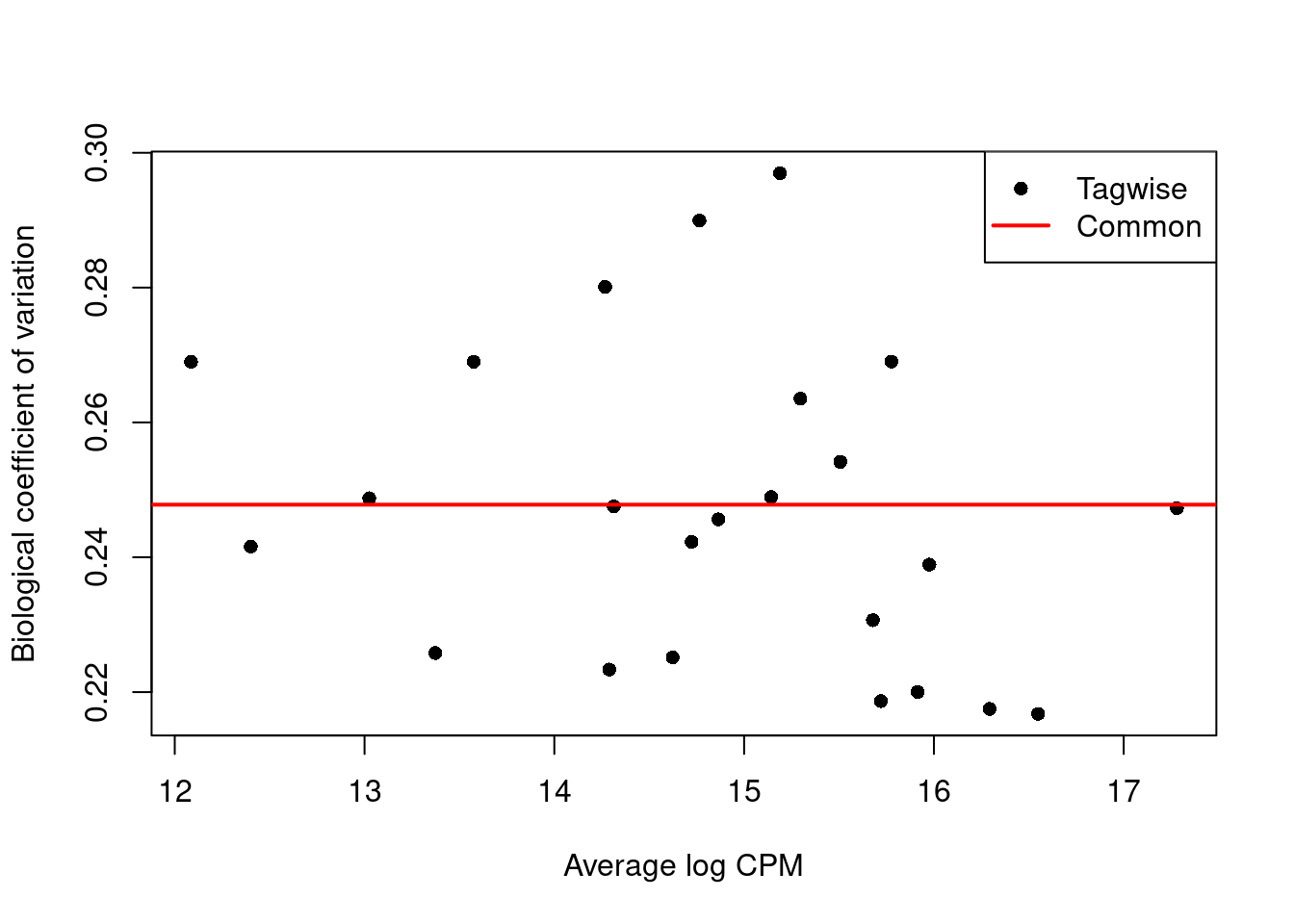
Figure 14.11: Biological coefficient of variation (BCV) for each label with respect to its average abundance. BCVs are defined as the square root of the NB dispersion. Common dispersion estimates are shown in red.
We repeat this process with the QL dispersion, again disabling the trend (Figure 14.12).
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.25 1.25 1.25 1.25 1.25 1.25## Min. 1st Qu. Median Mean 3rd Qu. Max.
## Inf Inf Inf Inf Inf Inf
Figure 14.12: QL dispersion estimates for each label with respect to its average abundance. Quarter-root values of the raw estimates are shown in black while the shrunken estimates are shown in red. Shrinkage is performed towards the common dispersion in blue.
We test for differences in abundance between td-Tomato-positive and negative samples using glmQLFTest().
We see that extra-embryonic ectoderm is strongly depleted in the injected cells.
This is consistent with the expectation that cells injected into the blastocyst should not contribute to extra-embryonic tissue.
The injected cells also contribute more to the mesenchyme, which may also be of interest.
## factor(tomato)TRUE
## Down 1
## NotSig 22
## Up 1## Coefficient: factor(tomato)TRUE
## logFC logCPM F PValue FDR
## ExE ectoderm -6.5663 13.02 66.267 1.352e-10 3.245e-09
## Mesenchyme 1.1652 16.29 11.291 1.535e-03 1.841e-02
## Allantois 0.8345 15.51 5.312 2.555e-02 1.621e-01
## Cardiomyocytes 0.8484 14.86 5.204 2.701e-02 1.621e-01
## Neural crest -0.7706 14.76 4.106 4.830e-02 2.149e-01
## Endothelium 0.7519 14.29 3.912 5.371e-02 2.149e-01
## Erythroid3 -0.6431 17.28 3.604 6.367e-02 2.183e-01
## Haematoendothelial progenitors 0.6581 14.72 3.124 8.351e-02 2.505e-01
## ExE mesoderm 0.3805 15.68 1.181 2.827e-01 6.258e-01
## Pharyngeal mesoderm 0.3793 15.72 1.169 2.850e-01 6.258e-0114.5.3 Handling composition effects
14.5.3.1 Background
As mentioned above, we do not use calcNormFactors() in our default DA analysis.
This normalization step assumes that most of the input features are not different between conditions.
While this assumption is reasonable for most types of gene expression data, it is generally too strong for cell type abundance - most experiments consist of only a few cell types that may all change in abundance upon perturbation.
Thus, our default approach is to only normalize based on the total number of cells in each sample, which means that we are effectively testing for differential proportions between conditions.
Unfortunately, the use of the total number of cells leaves us susceptible to composition effects. For example, a large increase in abundance for one cell subpopulation will introduce decreases in proportion for all other subpopulations - which is technically correct, but may be misleading if one concludes that those other subpopulations are decreasing in abundance of their own volition. If composition biases are proving problematic for interpretation of DA results, we have several avenues for removing them or mitigating their impact by leveraging a priori biological knowledge.
14.5.3.2 Assuming most labels do not change
If it is possible to assume that most labels (i.e., cell types) do not change in abundance, we can use calcNormFactors() to compute normalization factors.
This seems to be a fairly reasonable assumption for the WT chimeras where the injection is expected to have only a modest effect at most.
## [1] 1.0055 1.0833 1.1658 0.7614 1.0616 0.9743We then proceed with the remainder of the edgeR analysis, shown below in condensed format. Many of the positive log-fold changes are shifted towards zero, consistent with the removal of composition biases from the presence of extra-embryonic ectoderm in only background cells. In particular, the mesenchyme is no longer significantly DA after injection.
y.ab2 <- estimateDisp(y.ab2, design, trend="none")
fit.ab2 <- glmQLFit(y.ab2, design, robust=TRUE, abundance.trend=FALSE)
res2 <- glmQLFTest(fit.ab2, coef=ncol(design))
topTags(res2, n=10)## Coefficient: factor(tomato)TRUE
## logFC logCPM F PValue FDR
## ExE ectoderm -6.9215 13.17 70.364 5.738e-11 1.377e-09
## Mesenchyme 0.9513 16.27 6.787 1.219e-02 1.143e-01
## Neural crest -1.0032 14.78 6.464 1.429e-02 1.143e-01
## Erythroid3 -0.8504 17.35 5.517 2.299e-02 1.380e-01
## Cardiomyocytes 0.6400 14.84 2.735 1.047e-01 4.809e-01
## Allantois 0.6054 15.51 2.503 1.202e-01 4.809e-01
## Forebrain/Midbrain/Hindbrain -0.4943 16.55 1.928 1.713e-01 5.178e-01
## Endothelium 0.5482 14.27 1.917 1.726e-01 5.178e-01
## Erythroid2 -0.4818 16.00 1.677 2.015e-01 5.373e-01
## Haematoendothelial progenitors 0.4262 14.73 1.185 2.818e-01 6.240e-0114.5.3.3 Removing the offending labels
Another approach is to repeat the analysis after removing DA clusters containing many cells.
This provides a clearer picture of the changes in abundance among the remaining clusters.
Here, we remove the extra-embryonic ectoderm and reset the total number of cells for all samples with keep.lib.sizes=FALSE.
offenders <- "ExE ectoderm"
y.ab3 <- y.ab[setdiff(rownames(y.ab), offenders),, keep.lib.sizes=FALSE]
y.ab3$samples ## group lib.size norm.factors batch cell barcode sample stage
## 5 1 2268 1 5 cell_9769 AAACCTGAGACTGTAA 5 E8.5
## 6 1 993 1 6 cell_12180 AAACCTGCAGATGGCA 6 E8.5
## 7 1 2708 1 7 cell_13227 AAACCTGAGACAAGCC 7 E8.5
## 8 1 2749 1 8 cell_16234 AAACCTGCAAACCCAT 8 E8.5
## 9 1 4009 1 9 cell_19332 AAACCTGCAACGATCT 9 E8.5
## 10 1 6224 1 10 cell_23875 AAACCTGAGGCATGTG 10 E8.5
## tomato pool stage.mapped celltype.mapped closest.cell
## 5 TRUE 3 E8.25 Mesenchyme cell_24159
## 6 FALSE 3 E8.25 Somitic mesoderm cell_63247
## 7 TRUE 4 E8.5 Somitic mesoderm cell_25454
## 8 FALSE 4 E8.25 ExE mesoderm cell_139075
## 9 TRUE 5 E8.0 ExE mesoderm cell_116116
## 10 FALSE 5 E8.5 Forebrain/Midbrain/Hindbrain cell_39343
## doub.density sizeFactor label
## 5 0.029850 1.6349 19
## 6 0.291916 2.5981 6
## 7 0.601740 1.5939 17
## 8 0.004733 0.8707 9
## 9 0.079415 0.8933 15
## 10 0.040747 0.3947 1y.ab3 <- estimateDisp(y.ab3, design, trend="none")
fit.ab3 <- glmQLFit(y.ab3, design, robust=TRUE, abundance.trend=FALSE)
res3 <- glmQLFTest(fit.ab3, coef=ncol(design))
topTags(res3, n=10)## Coefficient: factor(tomato)TRUE
## logFC logCPM F PValue FDR
## Mesenchyme 1.1274 16.32 11.501 0.001438 0.03308
## Allantois 0.7950 15.54 5.231 0.026836 0.18284
## Cardiomyocytes 0.8104 14.90 5.152 0.027956 0.18284
## Neural crest -0.8085 14.80 4.903 0.031798 0.18284
## Erythroid3 -0.6808 17.32 4.387 0.041743 0.19202
## Endothelium 0.7151 14.32 3.830 0.056443 0.21636
## Haematoendothelial progenitors 0.6189 14.76 2.993 0.090338 0.29683
## Def. endoderm 0.4911 12.43 1.084 0.303347 0.67818
## ExE mesoderm 0.3419 15.71 1.036 0.314058 0.67818
## Pharyngeal mesoderm 0.3407 15.76 1.025 0.316623 0.67818A similar strategy can be used to focus on proportional changes within a single subpopulation of a very heterogeneous data set. For example, if we collected a whole blood data set, we could subset to T cells and test for changes in T cell subtypes (memory, killer, regulatory, etc.) using the total number of T cells in each sample as the library size. This avoids detecting changes in T cell subsets that are driven by compositional effects from changes in abundance of, say, B cells in the same sample.
14.5.3.4 Testing against a log-fold change threshold
Here, we assume that composition bias introduces a spurious log2-fold change of no more than \(\tau\) for a non-DA label. This can be roughly interpreted as the maximum log-fold change in the total number of cells caused by DA in other labels. (By comparison, fold-differences in the totals due to differences in capture efficiency or the size of the original cell population are not attributable to composition bias and should not be considered when choosing \(\tau\).) We then mitigate the effect of composition biases by testing each label for changes in abundance beyond \(\tau\) (McCarthy and Smyth 2009; A. T. L. Lun, Richard, and Marioni 2017).
## factor(tomato)TRUE
## Down 1
## NotSig 23
## Up 0## Coefficient: factor(tomato)TRUE
## logFC unshrunk.logFC logCPM PValue
## ExE ectoderm -6.5663 -7.0015 13.02 2.626e-09
## Mesenchyme 1.1652 1.1658 16.29 1.323e-01
## Cardiomyocytes 0.8484 0.8498 14.86 3.796e-01
## Allantois 0.8345 0.8354 15.51 3.975e-01
## Neural crest -0.7706 -0.7719 14.76 4.501e-01
## Endothelium 0.7519 0.7536 14.29 4.665e-01
## Haematoendothelial progenitors 0.6581 0.6591 14.72 5.622e-01
## Def. endoderm 0.5262 0.5311 12.40 5.934e-01
## Erythroid3 -0.6431 -0.6432 17.28 6.118e-01
## Caudal Mesoderm -0.3996 -0.4036 12.09 6.827e-01
## FDR
## ExE ectoderm 6.303e-08
## Mesenchyme 9.950e-01
## Cardiomyocytes 9.950e-01
## Allantois 9.950e-01
## Neural crest 9.950e-01
## Endothelium 9.950e-01
## Haematoendothelial progenitors 9.950e-01
## Def. endoderm 9.950e-01
## Erythroid3 9.950e-01
## Caudal Mesoderm 9.950e-01The choice of \(\tau\) can be loosely motivated by external experimental data. For example, if we observe a doubling of cell numbers in an in vitro system after treatment, we might be inclined to set \(\tau=1\). This ensures that any non-DA subpopulation is not reported as being depleted after treatment. Some caution is still required, though - even if the external numbers are accurate, we need to assume that cell capture efficiency is (on average) equal between conditions to justify their use as \(\tau\). And obviously, the use of a non-zero \(\tau\) will reduce power to detect real changes when the composition bias is not present.
Session Info
R version 4.0.4 (2021-02-15)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.2 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.12-books/R/lib/libRblas.so
LAPACK: /home/biocbuild/bbs-3.12-books/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] DropletUtils_1.10.3 scuttle_1.0.4
[3] MouseGastrulationData_1.4.0 scran_1.18.5
[5] edgeR_3.32.1 limma_3.46.0
[7] bluster_1.0.0 scater_1.18.6
[9] ggplot2_3.3.3 BiocSingular_1.6.0
[11] SingleCellExperiment_1.12.0 SummarizedExperiment_1.20.0
[13] Biobase_2.50.0 GenomicRanges_1.42.0
[15] GenomeInfoDb_1.26.4 IRanges_2.24.1
[17] S4Vectors_0.28.1 BiocGenerics_0.36.0
[19] MatrixGenerics_1.2.1 matrixStats_0.58.0
[21] BiocStyle_2.18.1 rebook_1.0.0
loaded via a namespace (and not attached):
[1] AnnotationHub_2.22.0 BiocFileCache_1.14.0
[3] igraph_1.2.6 splines_4.0.4
[5] BiocParallel_1.24.1 digest_0.6.27
[7] htmltools_0.5.1.1 viridis_0.5.1
[9] fansi_0.4.2 magrittr_2.0.1
[11] memoise_2.0.0 R.utils_2.10.1
[13] colorspace_2.0-0 blob_1.2.1
[15] rappdirs_0.3.3 xfun_0.22
[17] dplyr_1.0.5 callr_3.5.1
[19] crayon_1.4.1 RCurl_1.98-1.3
[21] jsonlite_1.7.2 graph_1.68.0
[23] glue_1.4.2 gtable_0.3.0
[25] zlibbioc_1.36.0 XVector_0.30.0
[27] DelayedArray_0.16.2 Rhdf5lib_1.12.1
[29] HDF5Array_1.18.1 scales_1.1.1
[31] pheatmap_1.0.12 DBI_1.1.1
[33] Rcpp_1.0.6 viridisLite_0.3.0
[35] xtable_1.8-4 dqrng_0.2.1
[37] bit_4.0.4 rsvd_1.0.3
[39] httr_1.4.2 RColorBrewer_1.1-2
[41] ellipsis_0.3.1 pkgconfig_2.0.3
[43] XML_3.99-0.6 R.methodsS3_1.8.1
[45] farver_2.1.0 CodeDepends_0.6.5
[47] sass_0.3.1 dbplyr_2.1.0
[49] locfit_1.5-9.4 utf8_1.2.1
[51] tidyselect_1.1.0 labeling_0.4.2
[53] rlang_0.4.10 later_1.1.0.1
[55] AnnotationDbi_1.52.0 munsell_0.5.0
[57] BiocVersion_3.12.0 tools_4.0.4
[59] cachem_1.0.4 generics_0.1.0
[61] RSQLite_2.2.4 ExperimentHub_1.16.0
[63] evaluate_0.14 stringr_1.4.0
[65] fastmap_1.1.0 yaml_2.2.1
[67] processx_3.4.5 knitr_1.31
[69] bit64_4.0.5 purrr_0.3.4
[71] sparseMatrixStats_1.2.1 mime_0.10
[73] R.oo_1.24.0 compiler_4.0.4
[75] beeswarm_0.3.1 curl_4.3
[77] interactiveDisplayBase_1.28.0 tibble_3.1.0
[79] statmod_1.4.35 bslib_0.2.4
[81] stringi_1.5.3 highr_0.8
[83] ps_1.6.0 lattice_0.20-41
[85] Matrix_1.3-2 vctrs_0.3.6
[87] pillar_1.5.1 lifecycle_1.0.0
[89] rhdf5filters_1.2.0 BiocManager_1.30.10
[91] jquerylib_0.1.3 BiocNeighbors_1.8.2
[93] cowplot_1.1.1 bitops_1.0-6
[95] irlba_2.3.3 httpuv_1.5.5
[97] R6_2.5.0 bookdown_0.21
[99] promises_1.2.0.1 gridExtra_2.3
[101] vipor_0.4.5 codetools_0.2-18
[103] assertthat_0.2.1 rhdf5_2.34.0
[105] withr_2.4.1 GenomeInfoDbData_1.2.4
[107] grid_4.0.4 beachmat_2.6.4
[109] rmarkdown_2.7 DelayedMatrixStats_1.12.3
[111] shiny_1.6.0 ggbeeswarm_0.6.0 Bibliography
Chen, Y., A. T. Lun, and G. K. Smyth. 2016. “From reads to genes to pathways: differential expression analysis of RNA-Seq experiments using Rsubread and the edgeR quasi-likelihood pipeline.” F1000Res 5: 1438.
Crowell, H. L., C. Soneson, P.-L. Germain, D. Calini, L. Collin, C. Raposo, D. Malhotra, and M. D. Robinson. 2019. “On the Discovery of Population-Specific State Transitions from Multi-Sample Multi-Condition Single-Cell Rna Sequencing Data.” bioRxiv. https://doi.org/10.1101/713412.
Finak, G., J. Frelinger, W. Jiang, E. W. Newell, J. Ramey, M. M. Davis, S. A. Kalams, S. C. De Rosa, and R. Gottardo. 2014. “OpenCyto: an open source infrastructure for scalable, robust, reproducible, and automated, end-to-end flow cytometry data analysis.” PLoS Comput. Biol. 10 (8): e1003806.
Lun, A., S. Riesenfeld, T. Andrews, T. P. Dao, T. Gomes, participants in the 1st Human Cell Atlas Jamboree, and J. Marioni. 2019. “EmptyDrops: distinguishing cells from empty droplets in droplet-based single-cell RNA sequencing data.” Genome Biol. 20 (1): 63.
Lun, A. T. L., and J. C. Marioni. 2017. “Overcoming confounding plate effects in differential expression analyses of single-cell RNA-seq data.” Biostatistics 18 (3): 451–64.
Lun, A. T. L., A. C. Richard, and J. C. Marioni. 2017. “Testing for differential abundance in mass cytometry data.” Nat. Methods 14 (7): 707–9.
McCarthy, D. J., and G. K. Smyth. 2009. “Testing significance relative to a fold-change threshold is a TREAT.” Bioinformatics 25 (6): 765–71.
Phipson, B., S. Lee, I. J. Majewski, W. S. Alexander, and G. K. Smyth. 2016. “Robust Hyperparameter Estimation Protects Against Hypervariable Genes and Improves Power to Detect Differential Expression.” Ann. Appl. Stat. 10 (2): 946–63.
Pijuan-Sala, B., J. A. Griffiths, C. Guibentif, T. W. Hiscock, W. Jawaid, F. J. Calero-Nieto, C. Mulas, et al. 2019. “A Single-Cell Molecular Map of Mouse Gastrulation and Early Organogenesis.” Nature 566 (7745): 490–95.
Richard, A. C., A. T. L. Lun, W. W. Y. Lau, B. Gottgens, J. C. Marioni, and G. M. Griffiths. 2018. “T cell cytolytic capacity is independent of initial stimulation strength.” Nat. Immunol. 19 (8): 849–58.
Robinson, M. D., D. J. McCarthy, and G. K. Smyth. 2010. “edgeR: a Bioconductor package for differential expression analysis of digital gene expression data.” Bioinformatics 26 (1): 139–40.
Robinson, M. D., and A. Oshlack. 2010. “A scaling normalization method for differential expression analysis of RNA-seq data.” Genome Biol. 11 (3): R25.
Scialdone, A., Y. Tanaka, W. Jawaid, V. Moignard, N. K. Wilson, I. C. Macaulay, J. C. Marioni, and B. Gottgens. 2016. “Resolving early mesoderm diversification through single-cell expression profiling.” Nature 535 (7611): 289–93.
Tung, P. Y., J. D. Blischak, C. J. Hsiao, D. A. Knowles, J. E. Burnett, J. K. Pritchard, and Y. Gilad. 2017. “Batch effects and the effective design of single-cell gene expression studies.” Sci. Rep. 7 (January): 39921.
Young, M. D., and S. Behjati. 2018. “SoupX Removes Ambient RNA Contamination from Droplet Based Single Cell RNA Sequencing Data.” bioRxiv.
Zheng, G. X., J. M. Terry, P. Belgrader, P. Ryvkin, Z. W. Bent, R. Wilson, S. B. Ziraldo, et al. 2017. “Massively parallel digital transcriptional profiling of single cells.” Nat Commun 8 (January): 14049.
14.6 Comments on interpretation
14.6.1 DE or DA? Two sides of the same coin
While useful, the distinction between DA and DE analyses is inherently artificial for scRNA-seq data. This is because the labels used in the former are defined based on the genes to be tested in the latter. To illustrate, consider a scRNA-seq experiment involving two biological conditions with several shared cell types. We focus on a cell type \(X\) that is present in both conditions but contains some DEGs between conditions. This leads to two possible outcomes:
We have described the example above in terms of clustering, but the same arguments apply for any labelling strategy based on the expression profiles, e.g., automated cell type assignment (Chapter 12). Moreover, the choice between outcomes 1 and 2 is made implicitly by the combined effect of the data merging, clustering and label assignment procedures. For example, differences between conditions are more likely to manifest as DE for coarser clusters and as DA for finer clusters, but this is difficult to predict reliably.
The moral of the story is that DA and DE analyses are simply two different perspectives on the same phenomena. For any comprehensive characterization of differences between populations, it is usually necessary to consider both analyses. Indeed, they complement each other almost by definition, e.g., clustering parameters that reduce DE will increase DA and vice versa.
14.6.2 Sacrificing biology by integration
Earlier in this chapter, we defined clusters from corrected values after applying
fastMNN()to cells from all samples in the chimera dataset. Alert readers may realize that this would result in the removal of biological differences between our conditions. Any systematic difference in expression caused by injection would be treated as a batch effect and lost when cells from different samples are aligned to the same coordinate space. Now, one may not consider injection to be an interesting biological effect, but the same reasoning applies for other conditions, e.g., integration of wild-type and knock-out samples (Section 14.4) would result in the loss of any knock-out effect in the corrected values.This loss is both expected and desirable. As we mentioned in Section 13.8, the main motivation for performing batch correction is to enable us to characterize population heterogeneity in a consistent manner across samples. This remains true in situations with multiple conditions where we would like one set of clusters and annotations that can be used as common labels for the DE or DA analyses described above. The alternative would be to cluster each condition separately and to attempt to identify matching clusters across conditions - not straightforward for poorly separated clusters in contexts like differentiation.
It may seem distressing to some that a (potentially very interesting) biological difference between conditions is lost during correction. However, this concern is largely misplaced as the correction is only ever used for defining common clusters and annotations. The DE analysis itself is performed on pseudo-bulk samples created from the uncorrected counts, preserving the biological difference and ensuring that it manifests in the list of DE genes for affected cell types. Of course, if the DE is strong enough, it may result in a new condition-specific cluster that would be captured by a DA analysis as discussed in Section 14.6.1.
One final consideration is the interaction of condition-specific expression with the assumptions of each batch correction method. For example, MNN correction assumes that the differences between samples are orthogonal to the variation within samples. Arguably, this assumption is becomes more questionable if the between-sample differences are biological in nature, e.g., a treatment effect that makes one cell type seem more transcriptionally similar to another may cause the wrong clusters to be aligned across conditions. As usual, users will benefit from the diagnostics described in Chapter 13 and a healthy dose of skepticism.